A quick investigation of how to speed up median filtering of 2D images
Author
Colin Kinz-Thompson
Published
October 29, 2023
Introduction
A median filter is a non-linear operation that replaces the value of a pixel by the median value of it’s neighbors. It can be very useful for removing salt and pepper noise from images. It’s not uncommon to see “salt” when a cosmic ray hits your camera detector (e.g., a pixel on an sCMOS chip). That type of noise will really mess up any downstream processing algorithms, because they usually don’t assume the presence of such noise. Unfortunately, median filters are very slow, so it’s not always practical to use them in a data analysis pipeline. So, I’ve done a little digging into how to speed them up for my Python code.
Literature
This follows the following two works:
Huang, T.S., Yang, G.J., Tang, G.Y. A Fast Two-Dimensional Median Filtering Algorithm. IEEE Transactions on Acoustics, Speech, and Signal Processing, 27(1), 1979.
Perreault, S., Hebert, P. Median Filtering in Constant Time. IEEE Transactions on Image Processing, 16, 2389–2394, 2007.
n.b., the Perreault manuscript reviews the Huang median filter.
Code
Here’s some non-optimized code to perform both the Huang and Perreault median filters on 2D, 8-bit images. Both of these are histogram-based median filters, where the idea is the the median value is found from a histogram instead of using a sorting filter. This means that, here, I’m maintaining an 256-bin histogram and looping through it until the cumulative counts reach 50% of the total counts. Also, w is the width of the kernel window, and must be an odd number. For the edges, they are treated as just having smaller neighborhoods.
Code
import numpy as npimport numba as nb@nb.njitdef med_huang_boundary(dd,w): nx,ny = dd.shape filtered = np.zeros_like(dd) histogram = np.zeros(256,dtype='int') w2 =int(w*w) r =int((w-1)//2)for i inrange(nx):### zero histogramfor hi inrange(256): histogram[hi] =0### initialize histogram j =0 nn =0for k inrange(-r,r+1):for l inrange(-r,r+1): hi = i+k hj = j+lif hi >=0and hj>=0and hi<nx and hj<ny: histogram[dd[hi,hj]] +=1 nn +=1## find median of histogram cut =int((nn//2)+1) count =0for ci inrange(histogram.size): count += histogram[ci]if count >= cut: filtered[i,j] = cibreak### run rowfor j inrange(1,ny): hjl = j-r -1 hjr = j+rfor k inrange(-r,r+1): hi = i+k## add RHS histogramif hi >=0and hi<nx and hjr<ny: histogram[dd[hi,hjr]] +=1 nn +=1## remove LHS histogramif hi >=0and hjl>=0and hi<nx: histogram[dd[hi,hjl]] -=1 nn -=1## find median of histogram cut =int((nn//2)+1) count =0for ci inrange(histogram.size): count += histogram[ci]if count >= cut: filtered[i,j] = cibreakreturn filtered@nb.njitdef med_perreault_boundary(dd,w): nx,ny = dd.shape filtered = np.zeros_like(dd) kernel_histogram = np.zeros(256,dtype='int') nn =0 column_histograms = np.zeros((ny,256),dtype='int') nnc = np.zeros(ny,dtype='int') w2 =int(w*w) r =int((w-1)//2)######### Initialize things i =0 j =0##initialize column histogramsfor j inrange(ny):for k inrange(r+1): column_histograms[j,dd[k,j]] +=1 nnc[j] +=1## initialize kernel histogramfor l inrange(r+1): kernel_histogram += column_histograms[l] nn += nnc[l]### first row doesn't get updatesfor j inrange(ny):if j >0: hjl = j - r -1 hjr = j + rif hjl >=0: kernel_histogram -= column_histograms[hjl] nn -= nnc[hjl]if hjr < ny: kernel_histogram += column_histograms[hjr] nn += nnc[hjr] cut =int((nn//2)+1) count =0for ci inrange(kernel_histogram.size): count += kernel_histogram[ci]if count >= cut: filtered[i,j] = cibreak######### Do Rows for i inrange(1,nx):for j inrange(ny):## start the next rowif j ==0: kernel_histogram *=0 nn =0 hit = i-r-1 hib = i+rfor l inrange(r+1):if hit >=0: column_histograms[l,dd[hit,l]] -=1 nnc[l] -=1if hib < nx: column_histograms[l,dd[hib,l]] +=1 nnc[l] +=1 kernel_histogram += column_histograms[l] nn += nnc[l]## go through the rowelse: hit = i-r-1 hib = i+r hjl = j-r-1 hjr = j+r#### update column histograms## topif hit >=0: column_histograms[hjr,dd[hit,hjr]] -=1 nnc[hjr] -=1## bottomif hib < nx: column_histograms[hjr,dd[hib,hjr]] +=1 nnc[hjr] +=1#### update kernel histogram## leftif hjl >=0: kernel_histogram -= column_histograms[hjl] nn -= nnc[hjl]## rightif hjr < ny: kernel_histogram += column_histograms[hjr] nn += nnc[hjr]## find median of kernel histogram cut =int((nn//2)+1) count =0for ci inrange(kernel_histogram.size): count += kernel_histogram[ci]if count >= cut: filtered[i,j] = cibreakreturn filtered
Timing
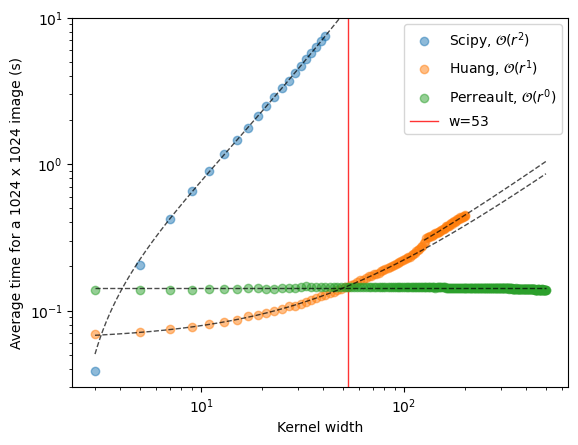
A sorting-based median filter scales with the size of the kernel window, i.e., \(\mathcal{O}(r^2)\), where \(2r+1\) is width of the kernel. Ignoring all overhead, and some issues with the edges, the Huang median filter scales with \(\mathcal{O}(r)\), and the Perreault median filter scales with \(\mathcal{O}(1)\). For Perreault, that means it is constant time WRT to kernel size – obviously, for all of these median filters, the larger the image, the larger the processing time.
Here’s a quick investigation of the timing
Code
##### Simulate imagefrom scipy.ndimage import uniform_filter,gaussian_filternx,ny = (1024,1024)## Make some blurry featuresd = np.random.seed(666)d = (np.random.rand(nx,ny)*256).astype('uint8')d = uniform_filter(d,8)d += (np.random.poisson(d.astype('double')*500)//100).astype('uint8')d = gaussian_filter(d,8).astype('uint8')## Add salt and pepper noisedd = d.copy()dd[np.random.rand(nx,ny)>.995] =255dd[np.random.rand(nx,ny)>.995] =0
Code
#### Plot the Imageimport matplotlib.pyplot as pltzoom =64vmin = d[:zoom,:zoom].min()vmax = d[:zoom,:zoom].max()fig,ax = plt.subplots(2,3,figsize=(9,6),dpi=300)#### Imageax[0,0].imshow(dd,cmap='Greys')ax[0,1].imshow(dd[:zoom,:zoom],cmap='Greys',interpolation='nearest')ax[0,2].imshow(dd[:zoom,:zoom],cmap='Greys',interpolation='nearest',vmin=vmin,vmax=vmax)#### Median filtered imageq = med_huang_boundary(dd,9)ax[1,0].imshow(q,cmap='Greys')ax[1,1].imshow(q[:zoom,:zoom],cmap='Greys',interpolation='nearest')ax[1,2].imshow(q[:zoom,:zoom],cmap='Greys',interpolation='nearest',vmin=vmin,vmax=vmax)ax[0,0].set_title('Full image')ax[0,1].set_title('Zoomed image')ax[0,2].set_title('Scaled image')ax[1,0].set_title('Filtered Full image')ax[1,1].set_title('Filtered Zoomed image')ax[1,2].set_title('Filtered Scaled image')fig.tight_layout()[[aaa.axis('off') for aaa in aa] for aa in ax]plt.show()
As you can seen in the plot of the timing, this Python code matches the theoretical scaling WRT the kernel size (\(r^2\), \(r^1\) and \(r^0\)). It also replicates the cross-over point between the Huang and Perreault approaches from the Perreault paper. As they explain, this is largely because of the overhead associated with initializing the column histograms in Perreault’s approach.
Overall, this isn’t very optimized Python code, which is part of why the Scipy filter is the fastest for a 3x3 kernel – however, that quickly becomes very slow.
I am planing to use these to remove salt and pepper noise for spot finding in single-molcule localization microscopy.